HTMX, Composición Funcional y el Problema del SEO
Construyendo páginas web que funcionan tanto para usuarios como para crawlers
Fecha:- htmxwebarquitecturabackend
Cuando decidí construir este blog usando HTMX, me topé con un problema arquitectónico bastante interesante. De esos que parecen simples en la superficie, pero que terminan afectando cómo estructuras toda tu aplicación.
Uno de los retos principales es lograr que la misma URL funcione tanto para visitas directas (desde buscadores, marcadores, enlaces compartidos) como para la navegación interna con HTMX.
El Dilema
HTMX propone extender la web tradicional de forma que puedas hacer peticiones HTTP directamente desde elementos HTML e intercambiar partes del DOM con la respuesta del servidor, todo con muy poca complejidad mental.
Pero esta simplicidad trae consigo una pregunta de diseño: cuando alguien hace clic en un enlace vía HTMX, lo ideal es enviar solo el fragmento de contenido. Pero cuando un crawler o usuario llega directamente a esa misma URL, necesita el documento HTML completo con navegación, estilos, scripts, todo el paquete.
Podrías resolver esto con endpoints separados, pero eso significa mantener dos versiones de cada ruta, y ya sabemos que cada línea de código extra es un dolor de cabeza a futuro.
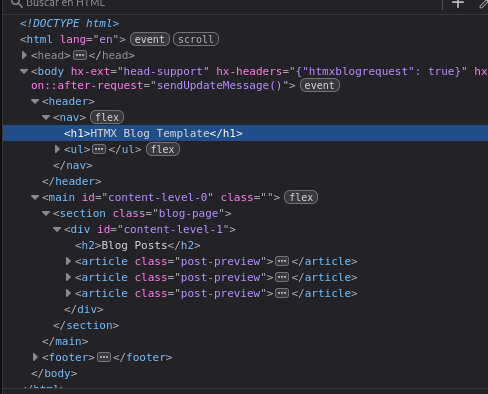
Visualizando las Páginas como Estructuras Anidadas: Composición Funcional
Aquí van dos ideas clave: la primera es que las páginas web son estructuras anidadas. Tu contenido vive dentro de una sección, que vive dentro del body, que vive dentro del documento HTML. Algo así:
plaintext
Documento HTML → Body → Sección → Contenido del Artículo
Cuando navegas dentro de tu sitio, la mayor parte de esta estructura se queda igual. Solo cambia el contenido más interno. Por eso las aplicaciones de una sola página se sienten tan rapidas, no tienen que volver a renderizar desde cero todo cada vez.
La segunda idea es que HTMX nos permite enviar únicamente ese contenido interno.
Juntando ambos enfoques, conseguimos el mismo beneficio de las aplicaciones de una sola página, pero con una diferencia clave: no es código del lado del cliente haciendo malabarismos con el enrutamiento interno o manejando estado, sino el servidor el que ya sabe qué contenido enviar.
Al ver este anidamiento, podemos tratar cada nivel de la estructura como una función que se puede componer. Cada función toma el contenido del siguiente nivel y lo envuelve en el HTML correspondiente.
javascript
function body(content) {
return `
<html>
<head>...</head>
<body>
<nav>...</nav>
<div id='content-slot'>
${content}
</div>
<footer>...</footer>
</body>
</html>
`;
}
function blogSection(content) {
return `
<section class='blog'>
<h1>Blog</h1>
<div id='post-slot'>
${content}
</div>
</section>
`;
}
function article() {
return `<article>¡Hola Mundo!</article>`;
}Ahora solo tienes que componer estas funciones para armar páginas completas:
javascript
// Página completa para peticiones externas
body(blogSection(article()))
// Solo el fragmento para peticiones HTMX
article()Detectando el Tipo de Petición
Para saber qué respuesta mandar, hay que distinguir entre peticiones externas e internas. HTMX lo hace super fácil con headers personalizados. Puedes agregar un header a todas las peticiones HTMX:
html
<body hx-headers='{"X-Requested-With": "htmx"}'>
<!-- Todas las peticiones HTMX desde aquí incluirán este header -->
</body>Y luego en el servidor:
javascript
app.get('/blog/mi-post', (req, res) => {
const content = article();
if (req.headers['x-requested-with'] === 'htmx') {
// Navegación interna - mandar solo el fragmento
return res.send(content);
}
// Petición externa - mandar la página completa
res.send(body(blogSection(content)));
});La Implementación Real
En este blog, uso un objeto PageFragment para representar cada nivel. Tiene el body HTML,
metadatos, estilos, todo lo que necesita esa pieza de la página. Luego tengo funciones que
componen estos fragmentos.
Cuando Express maneja una ruta, revisa el header personalizado headers['calaverd-blog']
1
y devuelve el fragmento directamente o lo envuelve en la plantilla completa.
Lo bonito es que las rutas se generan automáticamente desde una estructura de árbol, y cada ruta ya sabe cómo componerse:
javascript
// La estructura del sitio como un árbol
const siteMap = {
fragmentFunction: rootContent,
children: {
'es': {
fragmentFunction: mainPage,
children: {
'blog': {
fragmentFunction: blogPage,
children: {
'mi-post': {
fragmentFunction: postContent,
children: {}
}
}
}
}
}
}
};
// Las rutas se construyen recursivamente
function constructSite(map, route='/', fragmentFunctions=[]) {
const allFunctions = [...fragmentFunctions, map.fragmentFunction];
app.get(route, (req, res) => {
if (req.headers['calaverd-blog']) {
// Petición HTMX interna - mandar solo este fragmento
return res.send(map.fragmentFunction(null).bundle);
}
// Petición externa - componer todo desde la raíz
const fullPage = allFunctions.reduceRight(
(fragment, fun) => fun(fragment),
new PageFragment
);
res.send(fullPage.body);
});
// Construir las rutas hijas de forma recursiva
Object.entries(map.children).forEach(
([path, child]) => constructSite(child, route + path, allFunctions)
);
}Lo Que Ganas Con Esto
Esta arquitectura te regala varias cosas:
- SEO que funciona sin esfuerzo - Los crawlers reciben documentos HTML completos
- Navegación rápida - Los usuarios solo reciben el contenido que cambió
- URLs para compartir - Cada URL funciona como enlace directo
- Una sola fuente de verdad - Una ruta, una función de composición
- Cero problemas de hidratación - El servidor ya sabe qué mandar
Y todo esto solo con un conjunto de funciones componiendo strings de HTML, código simple y fácil de entender.
Los Compromisos
Para sitios enfocados en contenido con algo de interactividad, este patrón de composición funcional con HTMX funciona muy bien. Tienes la simplicidad de desarrollo del renderizado tradicional del servidor con la experiencia fluida de una aplicación de una sola página.
Claro, no hay solución universal, esto no es una varita mágica para todos los casos. Si necesitas manejo de estado complejo en el cliente, colaboración en tiempo real, o funcionalidad offline, vas a necesitar un framework de JavaScript para esas cosas.
Todo el sistema surge de partes simples que se componen. Cada función hace una cosa. La complejidad que ves es la que realmente existe.
El Helper de Enlaces
Para no tener que escribir los atributos de HTMX manualmente en cada enlace, uso una función helper que pone el target correcto según la profundidad de la URL:
javascript
function link(url, text) {
const levelNumber = Math.max(
[...url].filter(c => c === '/').length - 1,
0
);
return `<a href="${url}"
hx-get="${url}"
hx-target="#content-level-${levelNumber}"
hx-swap="innerHTML show:top swap:300ms"
hx-push-url="true">${text}</a>`;
}Los IDs de content-level se definen en las plantillas cuando creas la estructura de la página.
La Clase PageFragment
Cada pedazo de contenido está representado por un objeto PageFragment:
javascript
class PageFragment {
constructor() {
this.title = '';
this.description = '';
this.body = '';
this.styles = '';
this.lang = 'es';
this.keywords = [];
}
get bundle() {
return `
<head hx-head="re-eval">
<title>${this.title}</title>
<meta name="description" content="${this.description}">
</head>
${this.body}
`;
}
}El getter bundle envuelve el contenido con tags <head> marcados como hx-head="re-eval".
La extensión head-support de HTMX usa esto para actualizar el título de la página mientras navegas.
Pros y Contras
Lo Que Funciona Bien
- SEO - HTML completo para los crawlers
- Depuración - Abre la pestaña Network y ves exactamente qué manda el servidor
- Sin proceso de build - Módulos ES puros, nada más
- Rápido - El servidor manda HTML completo, sin esperar hidratación
- Ligero - ~14kb de HTMX vs más de 200kb en SPAs típicas de React
Las Desventajas
- Rutas manuales - Tienes que agregar cada página al mapa del sitio a mano
- Template literals - No hay resaltado de sintaxis sin plugins del editor
- No escala tan bien - El anidamiento profundo se vuelve complicado
Pruébalo
Si estás armando un blog, sitio de documentación, o alguna aplicación con mucho contenido, este patrón podría funcionarte. Empieza con páginas como funciones que se componen y ve a dónde te lleva.
Hice un repositorio de ejemplo simplificado que muestra la arquitectura básica: htmx_minimalist_blog_example 2
El ejemplo deja fuera el soporte bilingüe, el sistema de contenido basado en archivos, y otras características de producción para enfocarse solo en el patrón arquitectónico.